~今天要分享的是「支持向量機實作」~
有了前一篇的基礎知識後,馬上來看看怎麼用python程式碼實作吧!
支持向量機模型在sklearn套件底下:from sklearn import svm
#使用在分類問題svm.SVC(kernel=’linear’)
#使用在回歸問題svm.SVR(kernel=’linear’)
這裡有一個很重要的觀念是「核函數(kernel)是需要事先決定的」,官方給予的核函數可以選擇的有:linear(線性), poly(多項式), rbf(高斯), sigmoid(S型函數), precomputed(預先計算,意思就是程式不計算核函數,而是用預先已經計算好的核函數),每個方法會導致模型有不同的複雜性與計算時間,所以要根據問題選擇合適的方法。
若想要了解更詳細的使用方法可以使用help()語法或是到scikit-learn的官網查看(https://scikit-learn.org/stable/modules/classes.html#module-sklearn.svm)
[程式碼實作]
迴歸問題:使用sklearn的資料集”boston”進行分析
import pandas as pd
from sklearn.datasets import load_boston
boston = load_boston()
boston_data=pd.DataFrame(boston['data'],columns=boston['feature_names'])
print("Data數據:",boston_data.head())
print("===============================")
boston_target=pd.DataFrame(boston['target'],columns=['target'])
print("目標數據:",boston_target.head())
print("===============================")
X=boston_data[["CRIM",'ZN',"INDUS","CHAS","NOX","RM","AGE","DIS","RAD","TAX","PTRATIO","B","LSTAT"]]
y=boston_target['target']
from sklearn.model_selection import train_test_split
X_train, X_test,y_train,y_test = train_test_split(X,y,test_size=0.3)
from sklearn import svm
svr = svm.SVR(kernel = 'linear')
svr.fit(X_train,y_train)
print("解釋力:",svr.score(X_test,y_test))
print("===============================")
from sklearn.metrics import mean_squared_error
from math import sqrt
svr_pred = svr.predict(X_test)
rmse = sqrt(mean_squared_error(y_test, svr_pred))
print("rmse: %.3f" % rmse)
print("===============================")
print("目標變數平均值:",boston_target['target'].mean())
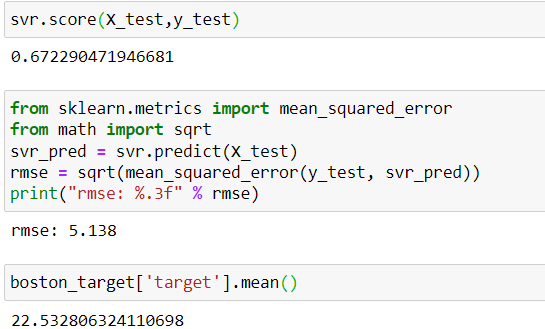
由結果可以得知,此模型的解釋力約有0.67,且目標變數裡的數據平均值約為22.53,模型誤差只有約5.14,所以算是可以參考的模型。
分類問題:使用sklearn的資料集”iris”進行分析
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
iris_data = pd.DataFrame(iris['data'],columns=iris['feature_names'])
print("Data數據:",iris_data.head())
print("===============================")
iris_target=pd.DataFrame(iris['target'],columns=['target'])
print("目標數據:",iris_target.head())
print("===============================")
X=iris_data[['sepal length (cm)','sepal width (cm)','petal length (cm)','petal width (cm)']]
y=iris_target['target']
from sklearn.model_selection import train_test_split
X_train, X_test,y_train,y_test = train_test_split(X,y,test_size=0.3)
from sklearn import svm
svc = svm.SVC(kernel = 'linear')
svc.fit(X_train,y_train)
from sklearn.metrics import classification_report,confusion_matrix
svc_pred= svc.predict(X_test)
print("混淆矩陣:",confusion_matrix(y_test,svc_pred))
print("======================================================\n")
print("模型評估指標:",classification_report(y_test,svc_pred))
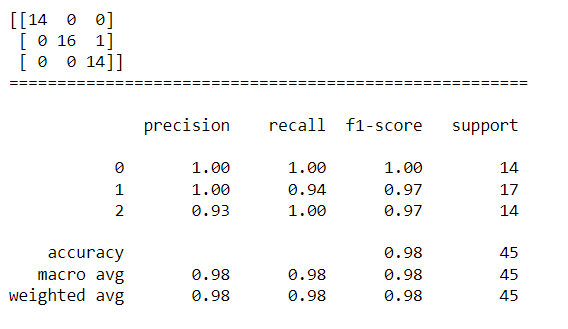
由結果可以得知,測試資料中只有一筆原本分類為第2類的樣本被模型預測成第1類,因此出現了一點誤差,但整體正確率高達0.98,所以是一個很優秀的模型。


 iThome鐵人賽
iThome鐵人賽